Ancora oggi quando faccio le mie lezioni sul web 2.0 e presento il caso dei wiki intesi come strumento per la costruzione collaborativa di un sapere enciclopedico, c’è sempre qualche studente – più polemico, più smaliziato, comunque scettico – che mi fa notare che non possa essere considerato un sapere valido, dato che non si conosce la paternità delle persone che ci scrivono su.
Ovvero: come può essere affidabile Wikipedia se chi ci scrive non è certificato per quelle competenze (tra l’altro, mutatis mutandis, è la stessa critica fatta da Civiltà Cattolica a questi strumenti).
Di solito la mia reazione è di accettazione della critica, che provvedo a smontare in maniera articolata: la ricerca fatta da Nature che contrappose l’affidabilità di Wikipedia contro l’Enciclopedia Britannica, la presenza di strumenti tecnici che consentono il controllo del wiki-spamming e così via dicendo.
Di solito però faccio riflettere sul fatto che le voci Wikipedia (spesso le più controverse) sono sottoposte ad un dibattito piuttosto articolato da parte degli utenti che editano quella voce specifica.
Per argomentare su questo uso la mia competenza da sociologo, da oggi però avrò un altro strumento.
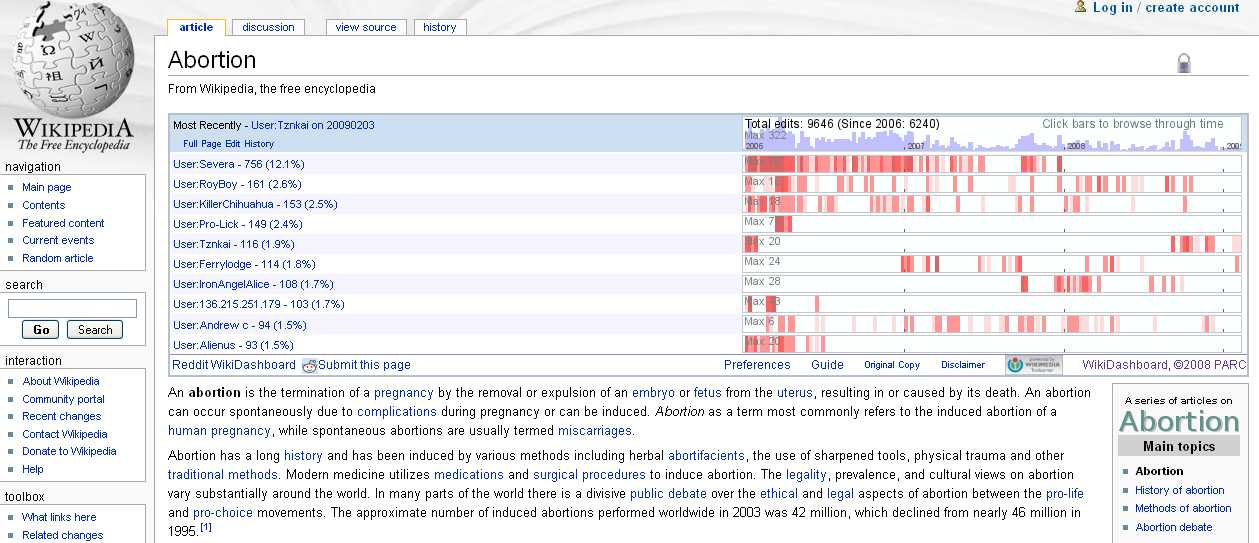
Mi riferisco a Wikidashboard, un’applicazione messa a punto da Ed Chi, ricercatore senior di augmented social cognition del leggendario Xerox PARC.
In pratica questa applicazione consente di cercare voci specifiche dentro wikipedia e di visualizzarne alcune statistiche sul “ciclo di vita” di quella voce: chi ha scritto qualche passaggio, quando l’ha scritto, l’ultimo editing a quando risale, e così via dicendo.
Nell’immagine sopra vedete la visualizzazione della voce “aborto” (più che controversa).
Tra l’altro questa applicazione consente di visualizzare in formato grafico tutte queste informazioni: in questo modo diventa uno strumento aggiuntivo per valutare la bontà di una voce wikipedia.
Credo che sarà questo lo strumento che userò a sostegno dell’argomentazione di chi (giustamente) solleverà la questione: “Chi garantisce per la bontà del contenuto di Wikipedia?”
Una risposta potrebbe essere “l’intelligenza collettiva”, ma se lo dici senza provarlo suona retorico.
Anche l’ipotesi ‘probabilistica’ di Chris Anderson mi sembra interessante: avere buone probabilita’ di avere delle informazioni esaurientemente esatte a fronte di uno sterminato numero di ‘voci’ presenti…
Effettivamente l’osservazione è interessante, ma credo che sia un “sintomo” di un processo di aggregazione. Ovvero io posso avere un’informazione non completamente vera, e posso via via affinarla con il confronto con gli altri consentito dalla piattaforma: se ci pensi è il meccanismo della maieutica socratica…
Però l’osservazione è più che pertinente e grazie per averla postata 🙂